Google Webmaster Tools IX. – soubor robots.txt

Jak jsem slíbila v minulém díle, je čas se seznámit blíže se souborem robots.txt. Jedná se o soubor – textový dokument - který obsahuje instrukce pro prohledávače (roboty). Slouží k usnadnění jejich práce, jelikož jim říká, jaké části webu neprocházet a zbytečně se jimi nezdržovat, popřípadě jaké části jsou jim zakázané (citlivá data apod.). Každý robot, který přijde na váš web, by měl nejdříve ze všeho zavítat právě do tohoto souboru. Název souboru („robots.txt“) musí být vždy psán malými písmeny a být umístěn v kořeni webu (hned za doménou 1.řádu a lomítkem, například .cz/) – u naší půjčovny dodávek je to tedy takto: http://www.primaautopujcovna.cz/robots.txt.
Nástroj na testování souborů robots.txt
Právě v této sekci naleznete soubor robots.txt. Získáte v ní tytéž informace (tentýž soubor) jako kdybyste zadali do adresního řádku výše zmíněným způsobem adresu URL – např. www.primaautopujcovna.cz/robots.txt.
Soubor robots.txt zabraňuje prohledávačům (př. Googlebot, Seznambot atd.), aby procházely některé stránky na vašem webu. O tom, které stránky to jsou, rozhodujete vy sami. Důvodem pro tato omezení je usnadnění práce robotovi – aby se zbytečně nezdržoval procházením „nedůležitých“ částí webu jako je admin, různé pluginy, komenty pod články apod. Jednotlivá omezení si v něm nastavíte sami a soubor robots.txt pak umístíte na váš FTP server (jak pracovat s FTP serverem se dozvíte v druhé části tohoto článku).
Soubor robots.txt obsahuje jakýsi seznam příkazů, které (některé) prohledávače smějí či nesmějí procházet. Používá příkazy typu Allow (Povolit) nebo Disallow (Zakázat). Pokud tedy nějakou adresu URL v souboru zakážete, nebude se (s největší pravděpodobností) objevovat ve výsledcích vyhledávání.
Tyto příkazy berme však spíše jako doporučení, nejsou to pravidla, kterými se vyhledávače musejí řídit a proto je dobré, obzvlášť v případě citlivých dat, nastavit ještě další zabezpečení (např. ochranu soukromých souborů na serveru pomocí hesla či vložením metaznaček do kódu HTML – např. noindex). Zabezpečení pomocí metaznaček se nastavuje pro každou stránku separátně přidáním metaznačky do sekce
:
- zakazuje indexování stránky většině prohledávačů
- zakazuje indexování prohledávačům společnosti Google
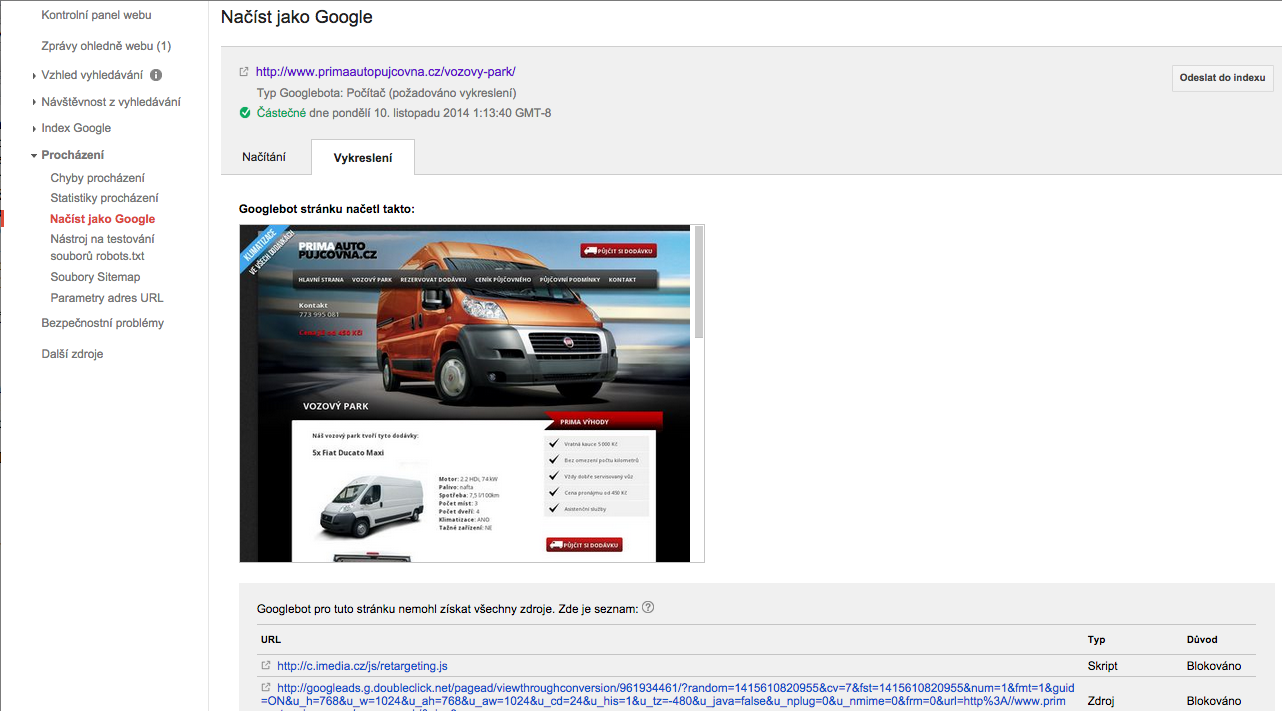
Pokud se vaše stránka i nadále objevuje ve výsledcích vyhledávání, je pravděpodobné, že ji od doby, kdy jste metaznačku přidali, ještě robot neprocházel. Pokud byste tento proces chtěli urychlit, stačí v nástroji Google Webmaster Tools v sekci Načíst jako Google zažádat o opětovné procházení stránky (volba Odeslat do indexu –screen 1).
SCREEN 1
Jak napsat soubor robots.txt?
Soubor robots.txt je obyčejný textový soubor (dá se vytvořit třeba v poznámkovém bloku) a používá dva klíčové termíny – Disallow a User-Agent. Jak již víme, slovo Disallow slouží k zakázání přístupu robotovi na některé adresy URL. User-agent je vlastně synonymum pro robota. Existuje opravdu velké množství robotů (http://www.robotstxt.org/db.html ), nejznámější z nich jsou pro nás Googlebot a Seznambot. Chcete-li robotu povolit přístup k některému adresáři, který je podřízen adresáři zakázanému, přiřadíte k němu naopak příkaz Allow (Povolit).
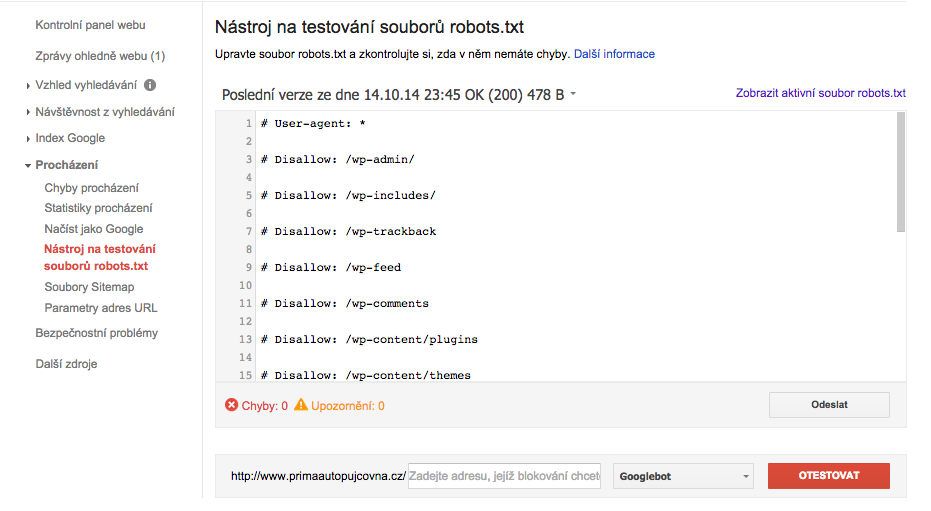
Jak vidíte na screenu 2 (nebo také po kliknutí na volbu Zobrazit aktivní soubor robots.txt – screen 3), do souboru robots.txt zapisujeme tato slova vždy následovaná dvojtečkou. Jeden záznam obsahuje tyto tři řádky:
User-agent: (následuje název robota, na kterého se bude příkaz vztahovat)
Disallow: (následuje URL, kterou chci zakázat)
Allow: (následuje URL obsaženou v zakázaném adresáři, kterou chci povolit)
SCREEN 2 SCREEN 3
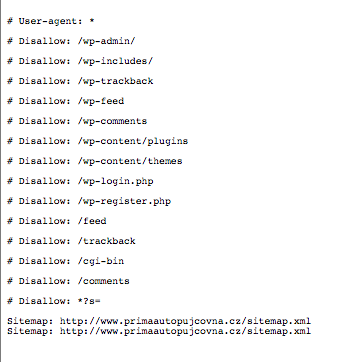
Do souboru robots.txt můžete vložit libovolný počet záznamů, přičemž každý z nich může obsahovat několik řádků Disallow pro několik robotů user-agent. Pokud chcete, aby příkaz platil pro všechny prohledávače, zapíšete u user-agent pouze hvězdičku:
User-agent: *
Disallow: /
- lomítko za Disallow znamená zákaz procházení pro celý web, celý tento příkaz tedy říká, že všechny prohledávače mají zakázáno procházet všechny stránky webu X pokud by tam lomítko nebylo a za Disallow by byl tedy ponechán prázdný prostor, bylo by všem robotům povoleno procházet vše
Uvedu ještě další příklady z našich screenů 2, 3:
User-agent: * - všem prohledávačům zakazujeme následující:
Disallow: /wp-admin/ - lomítkem na konci zakazujeme procházení adresáře /wp-admin/, ne však jeho dalších podsložek
Disallow: /wp-trackback - bez lomítka na konci zakazujeme procházení adresáře /wp-trackback/ včetně všech podsložek
Disallow: /wp-content/themes - zakazujeme procházení podsložky /themes/ včetně jejích dalších podsložek
Disallow: /wp-login.php - zakazujeme procházení PHP souboru wp-login.php
Co lze ještě zakázat/povolit:
User-agent: Seznambot
Disallow: /
User-agent: Googlebot
Disallow:
- tento zápis říká, že Seznambot nesmí nikam (lomítko za Disallow), zatímco Googlebot smí všude (prázdné místo za Disallow)
User-agent: *
Disallow: /en/
User-agent: Googlebot
Disallow: /cs/
- zdálo by se, že tento zápis znamená, že žádný robot nesmí do adresáře /en/, Googlebot nesmí do adresáře /cs/
- pravda je ale taková, že tím, že někde v zápisu zmiňujete Googlebot, přestávají pro něj automaticky platit pravidla platící pro * (všechny user-agenty) a výsledkem je tedy to, že Googlebot sice nesmí do adresáře /cs/, ale smí do /en/
- pokud bychom chtěli, aby nesměl ani do jednoho z nich, zápis by vypadal takto:
User-agent: *
Disallow: /en/
User-agent: Googlebot
Disallow: /cs/
Disallow: /en/
Zákazy můžeme ještě upřesnit pomocí hvězdičky:
User-agent: Seznambot
Disallow: /*kniha
- tento zápis zakazuje Seznambotu procházet stránky, které ve své URL kdekoli obsahují slovo „kniha“
User-agent: Googlebot
Disallow: /komentare/$
- Googlebot sice nesmí stahovat výchozí dokument v adresáři /komentare/, ale smí stahovat všechny ostatní soubory v tomto adresáři